


หนึ่งในเรื่องที่เป็นความท้าทายของการรับมือภัยคุกคามทางไซเบอร์ คือการเฝ้าระวังและตอบสนองต่อการโจมตีที่มีรูปแบบและเทคนิคเปลี่ยนแปลงอยู่ตลอดเวลา แนวทางการตรวจจับโดยใช้ signature หรือข้อมูลที่บ่งบอกลักษณะเฉพาะของรูปแบบการโจมตีเพียงอย่างเดียวนั้นอาจไม่เพียงพอ จำเป็นต้องอาศัยการตรวจจับแบบ anomaly หรือการวิเคราะห์พฤติกรรมผิดปกติร่วมด้วย เพื่อให้มีความครอบคลุมมากยิ่งขึ้น ซึ่งถึงแม้ว่าในปัจจุบันจะมีเครื่องมือที่ช่วยอำนวยความสะดวกในการตรวจจับเหตุการณ์ในลักษณะดังกล่าวได้ แต่การที่ทีมวิเคราะห์สามารถเข้าใจแนวทางการทำงานของเครื่องมือ หรือสามารถค้นหาความผิดปกติที่เครื่องมือยังไม่สามารถตรวจจับได้ ก็จะช่วยให้การตอบสนองต่อภัยคุกคามนั้นมีความแม่นยำมากยิ่งขึ้น
กระบวนการทำ incident response ตามข้อแนะนำ NIST SP 800-61r2 นั้นแบ่งออกได้เป็น 4 ขั้นตอน โดยในบทความนี้จะเน้นในส่วนที่ 2 ซึ่งเป็นหัวข้อ detection and analysis จุดประสงค์เพื่อให้ผู้ที่ทำงานด้านการวิเคราะห์ภัยคุกคามเข้าใจแนวทางการตรวจจับและวิเคราะห์พฤติกรรมที่เป็นอันตราย โดยจะอ้างอิงประเด็นสำคัญจากเอกสาร 2 ฉบับ คือ Technical Approaches to Uncovering and Remediating Malicious Activity กับ Federal Government Cybersecurity Incident and Vulnerability Response Playbooks และแบ่งเนื้อหาออกเป็น 3 ส่วน คือ ข้อมูล log ที่ควรเก็บ, แนวทางการวิเคราะห์พฤติกรรมผิดปกติ และ ข้อแนะนำในการรับมือ
Part 1: ข้อมูล log ที่ควรเก็บ
การพิจารณาว่าควรเก็บ log อะไรบ้าง อาจจะตั้งต้นจากสิ่งที่ต้องเก็บตามกฎหมาย (เช่น พรบ.คอมพิวเตอร์ 2564) จากนั้นเพิ่มเติมให้ครอบคลุมตามข้อกำหนดของ audit หรือ regulator แล้วกำหนด use case กับระดับความเร่งด่วนสำคัญของแต่ละเหตุการณ์
อีกแนวทางที่สามารถทำได้ คือการเลือก use case ขึ้นมาก่อน (เช่น อ้างอิงจาก Technique ใน MITRE ATT&CK ที่ผู้โจมตีนิยมใช้) จากนั้นจัดทำความเชื่อมโยงของ log source กับ Technique แต่ละประเภท แล้วระบุ indicator เพื่อให้สามารถนำไปจัดทำเป็น detection rule ต่อได้ โดยการเลือก use case นั้นสามารถพิจารณาได้จากหลายกรณี เช่น กิจกรรมที่ไม่สอดคล้องกับ IT security policy ขององค์กร การแจ้งเตือนจากอุปกรณ์ security analytics ข้อมูลจาก threat intelligence หรือข้อมูลจากแหล่งอื่นๆ ที่เป็นประโยชน์ต่อการเฝ้าระวังเหตุการณ์ผิดปกติ
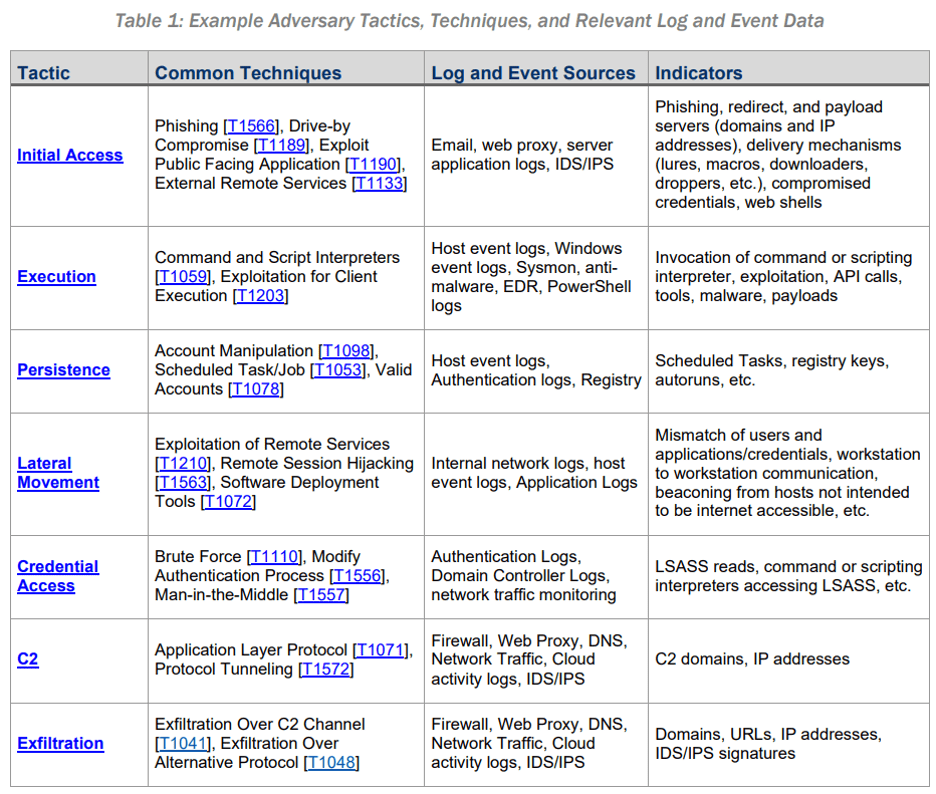
การเลือก indicator เพื่อนำมาสร้าง detection rule อาจประเมินได้จากช่องทางการโจมตีและผลกระทบที่จะเกิดขึ้นกับระบบที่ต้องการเฝ้าระวัง เช่น ผู้โจมตีสามารถเข้าถึงระบบดังกล่าวได้จากช่องทางใดบ้าง มี account ใดบ้างที่ได้สิทธิ์ระดับสูง หากโจมตีสำเร็จผู้โจมตีสามารถติดตั้งมัลแวร์หรือสร้าง backdoor สำหรับเข้ามายังระบบในภายหลังได้ด้วยวิธีใดบ้าง สามารถใช้ระบบดังกล่าวในการทำ lateral movement ไปยังระบบอื่นๆ ในองค์กร หรือสามารถ transfer ข้อมูลสำคัญออกจากระบบที่ถูกโจมตีได้โดยตรงหรือไม่ เป็นต้น ซึ่งข้อมูลเหล่านี้สามารถหา event ที่เกี่ยวข้องเพื่อนำมาสร้างเป็น logic ของ detection rule ได้
Part 2: แนวทางการวิเคราะห์พฤติกรรมผิดปกติ
หลังจากที่เลือก log source และประเมิน indicator ตามรูปแบบของภัยคุกคามที่เป็นไปได้ ขั้นตอนถัดมาคือการกำหนดเงื่อนไขเพื่อตรวจจับหรือค้นหาเหตุการณ์ที่ผิดปกติ โดยสามารถแบ่งออกได้เป็น 4 แนวทาง ดังนี้
- Indicator of Compromise (IOC) Search – เป็นการนำข้อมูลที่ถูกระบุว่าเป็นอันตราย (เช่น domain, IP, file hash) มาค้นหาใน log โดยตรง ข้อดีคือมีความตรงไปตรงมาและโอกาสเกิด false positive ต่ำ แต่ข้อเสียคือการตรวจจับด้วย IOC สามารถถูก bypass ได้ง่าย หรือ IOC ประเภท network นั้นมีความ dynamic อาจเกิด false positive ได้เมื่อเวลาผ่านไประยะหนึ่ง
- Frequency Analysis – เป็นการหาความผิดปกติที่เกิดจากพฤติกรรมของมนุษย์ โดยนำ dataset มาวิเคราะห์เพื่อจัดทำเป็นกลุ่มของรูปแบบเหตุการณ์ที่เป็นการใช้งานตามปกติ และเฝ้าระวังเหตุการณ์ที่ไม่เข้ากับกลุ่มที่เคยถูกจัดไว้ เช่น การ login นอกเวลางาน การ login จากอุปกรณ์ที่ไม่เคยรู้จัก หรือการใช้ port ที่ไม่เคยถูกใช้งานมาก่อน
- Pattern Analysis – เป็นการหาความผิดปกติที่เกิดจากมัลแวร์หรือสคริปต์ที่ทำงานแบบอัตโนมัติ ซึ่งแตกต่างจากพฤติกรรมการใช้งานของมนุษย์ตามปกติ เช่น มีเหตุการณ์บางอย่างเกิดขึ้นซ้ำๆ ทุกวันในเวลาเดียวกัน
- Anomaly Analysis – ใช้นักวิเคราะห์ทำงานร่วมกับผู้ดูแลระบบ เพื่อค้นหาพฤติกรรมหรือ error ในระบบที่มีความผิดปกติแต่อาจยังไม่สามารถยืนยันได้อย่างชัดเจนว่าเป็นการโจมตีจริงหรือไม่
แนวทางการค้นหาความผิดปกติบน host โดยหลักๆ จะเน้นไปที่การวิเคราะห์ข้อมูลจาก process, application, file, user account, และ event log อื่นๆ ที่ปรากฏอยู่บนเครื่อง ซึ่งความผิดปกติบางอย่างนั้นค่อนข้างชี้ชัดว่าเป็นการโจมตี แต่บางอย่างอาจจำเป็นต้องสอบถามกับผู้ที่เกี่ยวข้องเพื่อยืนยันความถูกต้องของข้อมูล ตัวอย่างแนวทางการค้นหาความผิดปกติบน host เช่น
- มี process ที่พยายามเชื่อมต่อออกอินเทอร์เน็ตและส่งข้อมูลออกไปยังเครื่องปลายทางที่น่าสงสัย ซึ่งอาจเป็นพฤติกรรมของ botnet ที่พยายามส่งข้อมูลในลักษณะ beacon เพื่อรายงานตัวกับเครื่องที่ใช้ควบคุมและสั่งการ (command and control)
- พบ PowerShell command line ที่เป็นลักษณะ Base64-encoded ซึ่งมีแนวโน้มที่จะเป็นการหลบเลี่ยงการตรวจจับการรันคำสั่งอันตราย
- พบการล็อกอินที่มีลักษณะน่าสงสัย เช่น ล็อกอินสำเร็จจาก IP ที่ไม่เคยถูกใช้ล็อกอินมาก่อนหน้านี้
- พบบัญชีผู้ใช้ที่ไม่สามารถระบุได้ว่าเป็นของใครหรือถูกใช้งานเพื่อจุดประสงค์ใด
- พบการเรียกใช้งานโปรแกรมหรือสคริปต์จากพาธ temp ซึ่งตามปกติไม่ควรมีการติดตั้งหรือเรียกใช้งานโปรแกรมจากพาธดังกล่าว
แนวทางการค้นหาความผิดปกติบน network โดยหลักๆ จะเน้นไปที่การตรวจจับทราฟฟิก DNS การใช้งานโพโทคอลประเภท remote access (เช่น RDP, VPN, SSH) การใช้งานโพรโทคอลประเภท file transfer (เช่น FTP, torrent) หรือช่องทางการสื่อสารอื่นๆ ที่นอกเหนือจากการใช้งานทีได้รับอนุญาต ตัวอย่างแนวทางการค้นหาความผิดปกติบน network เช่น
- เครื่องภายในมีการเปิด port ให้เครือข่ายภายนอกเชื่อมต่อเข้ามาได้ ซึ่งเป็น port ที่ไม่ได้ขออนุญาตหรือไม่สามารถระบุได้ว่าเป็นบริการใด
- พบทราฟฟิกเพิ่มสูงขึ้นผิดปกติ ซึ่งอาจเป็นการ upload ข้อมูลออกไปยังเครือข่ายภายนอก หรือพบความถี่ของการส่งข้อมูลในลักษณะ pattern (เช่น มีการเชื่อมต่อออกไปทุกชั่วโมง) ซึ่งอาจเป็นพฤติกรรมของมัลแวร์
- พบการเชื่อมต่อออกไปยัง IP หรือ domain ที่ถูกระบุว่าเกี่ยวข้องกับมัลแวร์หรือการโจมตี โดยเฉพาะอย่างยิ่งหากมีการพยายามเชื่อมต่อออกไปหลายครั้งถึงแม้จะพบว่าการเชื่อมต่อดังกล่าวถูกบล็อค ซึ่งมีแนวโน้มสูงที่จะเป็นเหตุการณ์ที่เกิดจากเครื่องติดมัลแวร์
Part 3: ข้อแนะนำในการรับมือ
กระบวนการทำ incident response หลังจากขั้นตอน detection and analysis เมื่อสามารถยืนยันได้ว่าระบบปลายทางถูก compromise สำเร็จ ขั้นตอนถัดไปคือการทำ containment, eradication, and recovery ซึ่งเป็นการจำกัดขอบเขตความเสียหายเพื่อป้องกันไม่ให้ระบบที่ถูกโจมตีนั้นสามารถถูกใช้ในการแพร่กระจายไปยังระบบอื่นๆ ต่อ จากนั้นทำการลบมัลแวร์หรือแก้ไขสิ่งที่ผู้โจมตีเข้ามาสร้างไว้ และกู้ระบบให้กลับคืนมาทำงานได้ตามปกติ อย่างไรก็ตาม กระบวนการหนึ่งที่อาจก่อให้เกิดความเสี่ยง (หรืออาจก่อให้เกิดความเสียหายเพิ่มเติมได้) คือการดำเนินงานในขั้นตอนก่อนที่จะเปลี่ยนจาก analysis ไปเป็น containment
จุดประสงค์ของการทำ analysis คือเพื่อประเมินความเสียหาย ผลกระทบ หรืออาจรวมไปถึงการสืบหาช่องทางการโจมตีและความเชื่อมโยงกับกลุ่มผู้โจมตีที่อาจเกี่ยวข้อง ทั้งนี้ มีสองประเด็นหลักที่จำเป็นต้องระวัง คือการพยายามรักษาสภาพพยานหลักฐาน หรือยุ่งเกี่ยวกับ volatile data บนเครื่องที่ถูก compromise ให้น้อยที่สุด (เช่น ไม่ควร restart หรือ shut down ระบบก่อนที่จะมีการเก็บรวบรวมพยานหลักฐาน) และพยายามไม่ทำให้ผู้โจมตีตัวรู้ว่าถูกจับได้ (เช่น การ ping, เชื่อมต่อไปยัง IP, หรือเข้าเว็บไซต์ของผู้โจมตี) เพราะผู้โจมตีอาจเปลี่ยนวิธีการ หรืออาจดำเนินการทำลายหลักฐานหรือทำลายข้อมูลอื่นๆ บนระบบที่สามารถยึดครองได้
จุดประสงค์ของการทำ containment คือเพื่อจำกัดขอบเขตความเสียหายที่จะเกิดขึ้นหลังจากที่มีบางระบบถูกผู้โจมตียึดครองได้ ซึ่งมีหลายแนวทางในการดำเนินการ เช่น ตัดเครื่องที่ถูกโจมตีออกจากระบบเครือข่ายหลักขององค์กร บล็อกไม่ให้มีการเชื่อมต่อออกไปยัง IP หรือ domain ที่เกี่ยวข้องกับการโจมตี หรือระงับสิทธิ์การใช้งานบัญชีที่ถูกผู้โจมตีเข้าถึงโดยไม่ได้รับอนุญาต เป็นต้น อย่างไรก็ตาม การดำเนินการบางอย่างอาจต้องพิจารณาว่าได้มีการตรวจสอบครอบคลุมเพียงพอแล้วหรือยัง เพราะผู้โจมตีอาจเปลี่ยนวิธีการหรือใช้ช่องทางอื่นที่ยังไม่ถูกค้นพบ เชื่อมต่อกลับเข้ามายังระบบได้อีก เช่น หากบล็อคเฉพาะ IP หรือ domain ของผู้โจมตี ก็อาจเปลี่ยนไปใช้ IP หรือ domain ใหม่แล้วโจมตีกลับเข้ามาอีกรอบก็ได้ หรือการระงับสิทธิ์เฉพาะบัญชีที่ถูกผู้โจมตียึดครอง ก็อาจเปลี่ยนไปใช้บัญชีอื่นที่ยังไม่ถูกตรวจพบได้ เพราะฉะนั้นในช่วงก่อนที่จะทำ containment อาจต้องตรวจสอบรายการสิ่งที่ต้องดำเนินการให้ครบ รวมถึงอาจต้องมีการ monitor เพื่อตรวจจับเหตุการณ์ผิดปกติเพิ่มเติมหลังจากที่มีการทำ containment ไปแล้วด้วย

สรุป
การตรวจจับและวิเคราะห์ภัยคุกคามโดยอ้างอิงจากพฤติกรรมที่เป็นอันตราย และการเลือกแนวทางการจำกัดขอบเขตความเสียหายได้อย่างเหมาะสม เป็นส่วนหนึ่งที่สามารถช่วยให้องค์กรรับมือการโจมตีได้อย่างแม่นยำและครอบคลุม โดยไม่ว่าจะเป็นการจัดเก็บ log การค้นหาเหตุการณ์ผิดปกติ และการเลือกแนวทางรับมือเพื่อแก้ไขปัญหา นั้นเป็นสิ่งที่ต้องอาศัยความร่วมมือและการแลกเปลี่ยนข้อมูลระหว่างทีมผู้ดูแลระบบและทีมวิเคราะห์การโจมตี เพื่อให้มีข้อมูลที่เพียงพอและสามารถตัดสินใจได้ทันสถานการณ์
MFEC เป็นบริษัทให้คำปรึกษาและพัฒนาโซลูชันด้านไอทีอย่างครบวงจร เป็นส่วนสำคัญที่ช่วยสร้างรากฐานด้านไอทีให้กับลูกค้าชั้นนำในภาคธุรกิจต่าง ๆ ผสานความแข็งแกร่งในการให้บริการด้าน Cyber Security และโซลูชันไอทีให้กับลูกค้าในกลุ่มองค์กรมากกว่า20 ปี มีบริการศูนย์ปฏิบัติการเฝ้าระวังความมั่นคงปลอดภัย หรือ Cyber Security Operation Center (CSOC) ซึ่งนอกจากการเฝ้าระวังแบบ 24 ชั่วโมง ยังครอบคลุมถึงการวิเคราะห์ที่แม่นยำ ตลอดจนการ Response ที่ถูกต้องและทันท่วงทีอีกด้ว
สำหรับลูกค้าองค์กรและภาคธุรกิจที่สนใจใช้บริการ CSOC as service หรือบริการด้านอื่น ๆ ที่เกี่ยวข้องกับ Cyber Security สามารถติดต่อได้ที่ email : infosec@mfec.co.th

